1. Introduction
RAKE is commonly used for extracting keywords from text and it is crucial for tasks like tagging, search engines, SEO and summarization and it is part of natural language processing (NLP).
RAKE (Rapid Automatic Keyword Extraction) is use when:
- Need fast keyword extraction
- Don’t have labeled data
- Want an unsupervised approach
2. What is RAKE?
RAKE (Rapid Automatic Keyword Extraction) is an unsupervised algorithm that extract keyword by identifying most commonly occurring word phases in a document.
- It works on word co-occurrence and frequency
- Training data is not required
Table of Contents:
- Introduction
- What is RAKE?
- Library Installation
- Working
- Advantage
- Disadvantage
- RAKE vs Other NLP Libraries
- Use Cases
- Conclusion
3. Installation:
- User have to first download python from official website. (Click Here for Python Installation) 🫲
- After downloading python; user have to install it and add path in environment variable.
pip install rake-nltk“RAKE Python library tutorial”
4. Working:
- Text Processing:
- Convert text to lowercase
- Split into words
- Remove punctuation
2. Stopword Removal:
- Delete words like: of, and is, the;
- Those words don’t carry any meaning
3. Candidate Phrase Generation:
- Spilt text using stopwords
- Remaining phrases become candidate
4. Keyword Scoring:
- In each phrase combine score of words
- Rank Phrases – highest score = very important keyword
5. Scoring word:
Each word gets a score based on:
- Degree (co-occurrence with other words)
- Frequency
RAKE Formula (Core Concept)
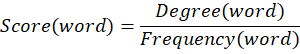
- Degree = number of times a word appears with other words
- Frequency = number of times the word appears
Code Example:
from rake_nltk import Rake
# Sample text
text = """
RAKE is a keyword extraction algorithm in NLP that identifies important phrases in a document.
It works by removing stopwords and analyzing word frequency.
"""
# Initialize RAKE
rake = Rake()
# Extract keywords
rake.extract_keywords_from_text(text)
# Get ranked keywords
keywords = rake.get_ranked_phrases()
print(keywords)Output Example:
[‘keyword extraction algorithm’, ‘important phrases’, ‘word frequency’, ‘rake’]
5. Advantage:
- Lightweight and Fast
- Easy to implement
- Work well on short text
- Training not required
6. Disadvantage:
- Heavily depends on stopword quality
- Doesn’t understand context
- Not ideal for complex language
7. RAKE vs other NLP Libraries:
- Uses ML model
- NLP Advance Feature
NLTK:
- Perform basic NLP task
- Manual keyword extraction needed
- Topic Modelling
- Complex than RAKE
👉 RAKE more efficient when you need simple and quick keyword extraction without ML
8. Use Cases:
- Search Engine
- Blog Tagging
- Document Summarization
- SEO keyword extraction
- Content recommendation
9. Conclusion:
RAKE is one of fastest and easiest keyword extraction process in NLP. While It is not powerful as modern ML Models, it is useful for quick tasks like content analysis and SEO.
#Python #NLP #Deeplearning #ArtificialIntelligence #ComputerScience
☎️ Contact Us For More Queries:-
📲 Call/WhatsApp: +91-9460060699
🌎 Website: www.techieprojects.com
📺 Instagram: @pythonprojects_
💡 Checkout Related Projects:-
1. Android App:- Click Here
2. Java Projects:- Click Here
3. OpenCV Projects:- Click Here
4. Data Science Projects:- Click Here
5. Data Analytics Projects:- Click Here
5. Deep Learning Projects:- Click Here
6. Cyber Security Projects:- Click Here
7. Machine Learning Projects:- Click Here
8. Image Processing Projects:- Click Here
9. Web Development Projects:- Click Here
10. Game Development Projects:- Click Here
11. Artificial Intelligence Projects:- Click Here
12. Database Management System:- Click Here
💬 If you found this helpful, share it with your friends!